A.I is out to get us. It will replace us all.. or maybe, it’s just another tool that we will get used to like calculators or iPhones.

If you are reading this post, chances are you are familiar with Artificial Intelligence, Deep Learning, Neural nets. I am not going to be pedantic and use them interchangeably.
If you don’t care for any of that, feel free to read this article as “Human in Machine Learning loop”. Or how to debug beyond metrics (smell a pattern in this blog?).
Let’s start with a practical example of something I built at Rent The Runway. RTR rents out high end designer dresses for a mass market price. We have a lot of folks who love us. And they are not shy about tagging us on their Instagram posts.
Wouldn’t it be great if we could show those Instagram photos on our product pages and help our customers find fashion inspiration through these high quality shots?
We already have photo reviews that our customers post on our site showing us how they wore it. It is a highly used feature for visitors. But customers have to submit to us directly for that to work.
My mind was set. It had to be done.
But how? While it is true that they tag #renttherunway or #myRTR, they don’t tag the exact dress name.
Obviously I brought a tank to a knife fight and built a convolutional neural net. This A.I that would look at these natural images and classify them as one of the thousands of dresses that we have currently on site. I named it DeepDress, but probably should have called it Dress2Vec… too late now. I used Torch to train and Benjamin’s waffle package to create an internal API that I can hit from any language. Since I have little patience, I used NVIDIA GPUs to speed up the training and tests.
I got all 30k Instagram posts at the time and I stored the metadata in Mongo (I know, I know but it’s great for unstructured).
Here is the code for that –
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| import urllib.request | |
| import json | |
| from pymongo import MongoClient | |
| import time | |
| def fetchAndStash(url, client): | |
| try: | |
| response = urllib.request.urlopen(url + '&count=100') | |
| f = response.read() | |
| payload = f.decode('utf-8') | |
| j = json.loads(payload) | |
| if j['meta']['code'] == 200 : # Request worked | |
| for i in j['data']: # Loop through Instagram posts and save them | |
| try: | |
| # Hardcoded Database/Collection names.. change this | |
| result = client.DeepDress.InstagramV4.insert({'_id' : i['link'], 'payload' : i, 'image' : i['images']['low_resolution']['url']}) | |
| except: | |
| print("bad batch url: " + url + '; tried to insert ' + i) | |
| with open('error', 'a') as of: | |
| of.write(f.decode('utf-8')) | |
| time.sleep(1) # Be nice | |
| fetchAndStash(j['pagination']['next_url'], client) # Follow the white rabbit | |
| else : | |
| print(url) | |
| except: | |
| print("Failed url ", url) | |
| def main(): | |
| client = MongoClient() | |
| url = 'https://api.instagram.com/v1/tags/renttherunway/media/recent/?client_id=your_client_id_here' | |
| fetchAndStash(url, client) # could hit stack overflow.. but unlikely | |
| if __name__ == "__main__": | |
| main() |
Then I looped through them and called my API to identify the dress and saved that.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| import urllib.request | |
| import json | |
| from pymongo import MongoClient | |
| import time | |
| from multiprocessing import Pool | |
| DEEP_DRESS_WGET = 'http://localhost/wget/?url=' | |
| DEEP_DRESS_PREDICT = 'http://localhost/predict/' | |
| def wget_deep_dress(url): | |
| serviceurl = DEEP_DRESS_WGET + url | |
| response = urllib.request.urlopen(serviceurl) | |
| f = response.read() | |
| j = json.loads(f.decode('utf-8')) | |
| return(j['file_id']) | |
| def predict_deep_dress(file_id, top_n): | |
| serviceurl = DEEP_DRESS_PREDICT + '?file_id=' + file_id + '&top_n=' + top_n | |
| response = urllib.request.urlopen(serviceurl) | |
| f = response.read() | |
| j = json.loads(f.decode('utf-8')) | |
| return(j) | |
| client = MongoClient() | |
| db = client.DeepDress | |
| instagram = db.InstagramV4 | |
| matches = db.MatchesV4 | |
| # already tagged | |
| ids = set([m['_id'] for m in matches.find()]) | |
| def match_and_save(i): | |
| try: | |
| if (i['_id'] not in ids): | |
| file_id = wget_deep_dress(i['image']) | |
| preds = predict_deep_dress(file_id, '3') | |
| result = matches.insert({'_id' : i['_id'], 'prediction' : preds}) | |
| time.sleep(1) # Be nice | |
| return(1) | |
| except: | |
| return(0) | |
| pool = Pool(processes=5) # Don't make this too high – rate limits | |
| totals = pool.map(match_and_save, instagram.find()) | |
| print(sum(totals), len(totals)) |
Mission accomplished and moving on.
Well my friends, if that were the case, I wouldn’t have written this post. So here is how a production system is really built.
One problem I knew ahead of time is that our inventory changes over time as we retire older styles and acquire new ones. DeepDress did not know of some very new dresses and none of the old ones. Old ones aren’t an issue since we wouldn’t want to display them anyway but there is a cold start problem that I hadn’t solved at the time.
Another issue is that I had trained the algorithm only on our dresses. While that is our bread and butter, we also rent bags, earrings, necklaces, bracelets, activewear, etc. I always start simple for v1. This means there were bound to be things classified incorrectly as the convnet sweats bullets trying to figure out which dress that Diane Von Furstenberg minaudiere looks like. We could use a lower bound on the probability of most likely class, but what should that threshold be?
Besides the above red flags, even if the identification were 100% accurate (ha), it would make sense to have someone in RTR verify that the image is in fact, fit for display on our site and consistent with our branding.
What we need to build is a gamified quick truther thingy that all our 200 employees in main office can log in during their lunch break and rate a few items. It better be interesting and fast because they have important things to do. It wouldn’t hurt to get verification of the same image from a few different folks so we build our confidence. Then there are nice to haves like responsive, reactive, and other fancy words that mean fun to use.
I could have built this in ruby or react or something that pleases my web developer friends. But I am a data scientist who is very familiar with R, so I built another shiny little thing in an hour. I am in good company. My friend Rajiv also loves understanding his A.I. creations in R.
Rough outline on what we want –
- Start with a random seed for each session
- Retrieve Instagram Images from that seed backwards
- User has to choose one of N options
- Upon choice, store the result back in Mongo
- Automatically move on to the next one (shiny is responsive)
- Every day, a job would restart the server, freezing what was done and starting on the next batch, moving back in time.
First we set up the global.R to get the relevant Instagram posts we will verify –
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| library(mongolite) | |
| # Connections to mongo | |
| instagram <- mongo(collection = "InstagramV4", db = "DeepDress", url = "mongodb://localhost", verbose = FALSE) | |
| matches <- mongo(collection = "MatchesV4", db = "DeepDress", url = "mongodb://localhost", verbose = FALSE) | |
| corrections <- mongo(collection = "CorrectionsV4", db = "DeepDress", url = "mongodb://localhost", verbose = FALSE) | |
| # Get Instagram data we saved earlier | |
| ids.df <- instagram$find(fields = '{"_id" : 1, "payload.created_time" : 1}') | |
| ids.df.simple <- data.frame(id = ids.df$`_id`, | |
| created_time = ids.df$payload$created_time, | |
| stringsAsFactors = FALSE) | |
| # Reorder by newest | |
| ids.df.simple <- ids.df.simple[order(-as.numeric(ids.df.simple$created_time)), ] | |
| # What has already been corrected by users | |
| ids.done <- corrections$find(fields = '{"id" : 1}') # What has already been corrected | |
| # What's left | |
| ids.df.todo <- setdiff(ids.df.simple$id, ids.done$id) |
Then we create ui.R that my colleagues will see –
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| library(shiny) | |
| shinyUI(fluidPage( | |
| # Application title | |
| titlePanel("Verify Auto-tagged dresses from Instagram"), | |
| # Sidebar with a slider input for number of bins | |
| sidebarLayout( | |
| sidebarPanel( | |
| textInput("email", "Your email", placeholder = "So that we can attribute the correction to you"), | |
| htmlOutput("instagram"), | |
| radioButtons("yesorno", "Accept tag?", | |
| c("Not a dress", "First", "Second", "Third", "None"), selected = "None"), | |
| actionButton("submit", "Submit"), | |
| helpText("Click the photo to see the original Instagram"), | |
| helpText("DeepDress AI might not know about some newer dresses. Esp dresses with <= 10 photo reviews"), | |
| helpText("The AI was written to match ANY PHOTO to our dresses. It does not know if what it is seeing is not a dress."), | |
| helpText("FAQ: Use 'Not a dress' if it is a Handbag, jacket, car or flower.. anything that's not a dress.") | |
| ), | |
| # Show a plot of the generated distribution | |
| mainPanel( | |
| htmlOutput("deepDress"), | |
| hr(), | |
| h4("Match probability"), | |
| textOutput("deepDressProb") | |
| ) | |
| ) | |
| )) |
Finally we need to hook up some logic –
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| shinyServer(function(input, output, session) { | |
| # Session level | |
| idx <- round(runif(1, 1, 2500)) # random place to start | |
| state <- reactive({ | |
| if(input$submit > 0) { # Not on first page load | |
| isolate({ # Don't get reactive on me now | |
| answer <- input$yesorno | |
| m <- matches$find(query = paste0('{"_id": "', ids.df.todo[idx], '"}'), fields = '{}' ,limit = 1, pagesize=1) | |
| answer.clean <- ifelse(answer == "First", | |
| m$prediction$styleNames[[1]]$style[1], | |
| ifelse(answer == "Second", | |
| m$prediction$styleNames[[1]]$style[2], | |
| ifelse(answer == "Third", | |
| m$prediction$styleNames[[1]]$style[3], | |
| answer))) | |
| datum <- data.frame(email = input$email, | |
| id = ids.df.todo[idx], | |
| answer = answer.clean, | |
| ts = Sys.time() | |
| ) | |
| corrections$insert(datum) | |
| }) | |
| } | |
| idx <<- idx + 1 # Keep on moving | |
| }) | |
| output$instagram <- renderPrint({ | |
| state() | |
| i <- instagram$find(query = paste0('{"_id": "', ids.df.todo[idx], '"}'), fields = '{}' ,limit = 1, pagesize=1) | |
| cat(paste0("<a href='", i$`_id`,"' target='_blank'>", | |
| "<img src='", i$image, "' />", | |
| "</a>")) | |
| }) | |
| getFirst <- reactive({ | |
| state() | |
| m <- matches$find(query = paste0('{"_id": "', ids.df.todo[idx], '"}'), fields = '{}' ,limit = 1, pagesize=1) | |
| }) | |
| output$deepDress <- renderPrint({ | |
| m <- getFirst() | |
| cat(paste0("<img src='", m$prediction$styleNames[[1]]$urls$imageURL, "' />")) | |
| }) | |
| output$deepDressProb <- renderText({ | |
| m <- getFirst() | |
| paste(round(m$prediction$styleNames[[1]]$probability), '%') | |
| }) | |
| }) |
And shiny does the rest. Here is what this looks like in practice –
This was so successful that in the two weeks the POC was up, we had 3,281 verifications. Some colleagues (thanks Sam/Sandy) did as many as 350+ verifications over that time. It should be pointed out that besides an announcement email, there was no other push to do this.
We found that there were a significant number of posts that were not even dresses. I guess our fashionistas really love us. This is not a problem I knew about going into building this and was certainly not expecting high probability scores for the suggested class in some cases. It helped me fix it by adding a class for “not a dress” with actual training data (and noise).
Most importantly, we answered important questions like what this cute puppy wore.

And if that isn’t the most satisfying result, I don’t know what is.
We have some amazing employees (hi Sam/Liz/Amanda) who have can remember single dress on site. For mere mortals, matching a photo to something we have is nearly impossible.
DeepDress A.I toiled through all 30k photos and narrowing each down to 3 possible choices from our thousands. But it is humans who really save the day. As a result we have a golden database of Instagram photos mapped to exact product that took advantage of both their strengths. Look at that – humans and A.I can play together.
Hopefully this example demonstrates why it is useful to use your resources (company employees) to check your systems beyond the metrics before releasing things in the wild. I end up using shiny a lot for these sort of internal demos because I slice and dice the results in R. But do them in whatever you are comfortable in and aggressively re-evaluate those choices should they reach production. For example, we will rewrite the truther in Ruby now that it will be production to comply with our other standards. For demos, I have no emotional attachment to any language (close your ears C++).
I’m sure you guessed that could not have been the only reason I built DeepDress and you would be right. But today’s not a day to talk about that.

 in the form
in the form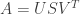
 is of size num_users and num_users
is of size num_users and num_users is a rectangular diagonal matrix of size num_users and num_products
is a rectangular diagonal matrix of size num_users and num_products is of size num_products and num_products
is of size num_products and num_products

 is of size num_users and num_categories and
is of size num_users and num_categories and  is of size num_products and num_categories, then we have a decent model that approximates
is of size num_products and num_categories, then we have a decent model that approximates  .
. 
 is the difference between observed data and our prediction.
is the difference between observed data and our prediction.  is simply a matrix with 1 where we have a value and 0 where we do not. Multiplying these two we are only considering the cost when we observe a value. We are using L2 regularization of magnitude
is simply a matrix with 1 where we have a value and 0 where we do not. Multiplying these two we are only considering the cost when we observe a value. We are using L2 regularization of magnitude  . We are going to divide by 2 to make all other math easier. The cost is relative so it doesn’t matter.
. We are going to divide by 2 to make all other math easier. The cost is relative so it doesn’t matter.




 is the set of all user-item pairings
is the set of all user-item pairings 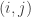 for which we have a predicted rating
for which we have a predicted rating 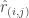 and a known rating
and a known rating  which was not used to learn the recommendation model.
which was not used to learn the recommendation model.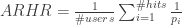
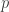 is the position of the item in a ranked list.
is the position of the item in a ranked list.






