
Vanity
We are all guilty of it. Every tech team wants to show off their stack as this big beautiful Ferrari they are proud of. What they often omit is what is glued together by duct tape and 20 other cars they built without engines.
I think this is disparaging to new data scientists. Creating these things is full of false starts and often you end up not where you intended to go, but a good enough direction. They need to see where experts fail, and where they prioritize a must have vs nice to have. Let’s get our hands dirty.
RTR tech is World class. This is going to be the story of how this team will be able to deliver that Ferrari in a month! I hope this gives you insight on how to build things in practice and take away some practical wisdom for that Lamborghini you are going to build.
Backstory
It was a couple of weeks ago that I was sitting in a room with Anushka (GM of Unlimited, our membership program), Vijay (Chief Data Officer, my boss) and Arielle (Director of Product Management, putting it all together). We had a singular goal – how to make product discovery for Unlimited faster. The current recommendations had served us well, but we now need new UX and algos to make this happen. We had learnt from surveys and churn analysis that this is the right thing to work on. But we were short on time from when we start. We had to have a recommendation engine in a month.

Unlimited is your subscription to Fashion. Members pay $139 a month for 3 items at a time. They can hold it for as long as they want. They can return them and get new ones, or buy them. The biggest selling point is our amazing inventory. We have a breadth of designer styles at high price points. So you can dress like a millionaire on a budget.
At high level, we want carousels of products, that are appropriate for that user’s style and fit, a la Netflix, Spotify. We want this to update online (current one is offline) and give recommendations to new users when they start. We want different sorts of carousels – ones made by the algorithms showcasing their styles, vs sorting others by our stylists. And still others saying “because you like X”.
This is naturally impossible in this timeline. However, I did build the first recommendation engine for RTR from the ground up all five years ago. I had also built the current recos for Unlimited when the program was new. We had a lot more existing pipelines and resources I could use. Plus I was getting help this time around, Sean, a bright young analyst who wants to get into Machine Learning.
This is the reality of startups. You can spend a lot of time getting something prioritized on the roadmap, and when it is, it’s a short window. And you can’t miss.
So we aren’t going to miss. And to keep me honest, I’m going to try to write about the process here. Fair warning, I’m not a habitual blogger and doing this after a full day of work, so we will see if this lasts.
What we have:
- Offline recos computed by a scala job
- Pixels (messages) coming back with what the user actually did
- MPP Data warehouse that can process pixels, orders, views, etc
- Serving pre-computed recos via a reco engine that is basically a giant cache. It serves user->products, user->events, event->products, products->products. All models pre-computed offline.
- An AI platform I built to understand images, called DeepDress, powering some products
- Lots of models from my previous research regarding our recommendations
We now have to deliver online recos, and by carousel.
My plan of attack:
- Reuse things we have built before
- Make the end-to-end pipe (data -> algo -> validation -> serving -> data)
- Make sure validation framework is in place, we need to know which metric correlates to outcome we really want to measure (churn).
- Keep it simple, we need a baseline we can improve on. Ideally two algorithms to compare.
- Allow for misses. Things aren’t going to be perfect, account for them up-front.
- Make sure Sean learns something tangible here that gets him excited about doing more things, not overwhelmed.
- Make sure any shortcuts are documented with TODOs and MEHs. We need to know where the duct tape is in context.
Let’s break it down into tracks – engineering, data science, design/product.
The engineering architecture
Before we agree on what to build, we need to agree on what success from the Engineering metrics looks like. So I proposed the following engineering metrics,
- Things will go wrong, we need safety valves:
- Code breaks – Uptime SLA (say 90%), should have fallbacks.
- Latency SLA:
- computation takes longer than say 200ms so we have to return something to the user.
- New recos reflect the actions taken by the user, in say less than 30 minutes. This means that recos should reflect actions taken by users at most 30 minutes ago.
- Flexible: We don’t know what model will work. We will change this often and experiment.
- Scaling: We need to be able to scale horizontally. This pipe should eventually replace our Classic (regular recos) pipe.
- Separation of concerns: What does Data Science do, what does Engineering do
- Language used: Engineering uses JAVA for all backend services. I have used C++ (wrapped in R) in the past, JAVA for another solver for fulfillment, scala for refactor of personalization with Anthony (who is now at Google).
Our simple proposal based on all this at the time is to create a scala library that we use to create the model. And the same library can used by the online portion at Engineering writes to load and predict from the model. This is the path of least resistance because JVM allows them to call it seamlessly, and we already have offline recommendations being computed by a Bayesian model written in scala.
The big thing here is that the JAVA portion (owned by Engineering) will have multiple fallbacks. For every type of recommendation, it can go to a set of carousels and products it can deliver. Strictly speaking, Data science ML library is research and the code to serve them is Engineering. If the ML library throws an exception, the engineering portion should know what to do about it (go to previous version of model, etc).
The other is scaling, each online serving shard only needs to know about a subset of users. We will use LSH tricks for this.
Here is the cartoon version of what we jointly proposed:
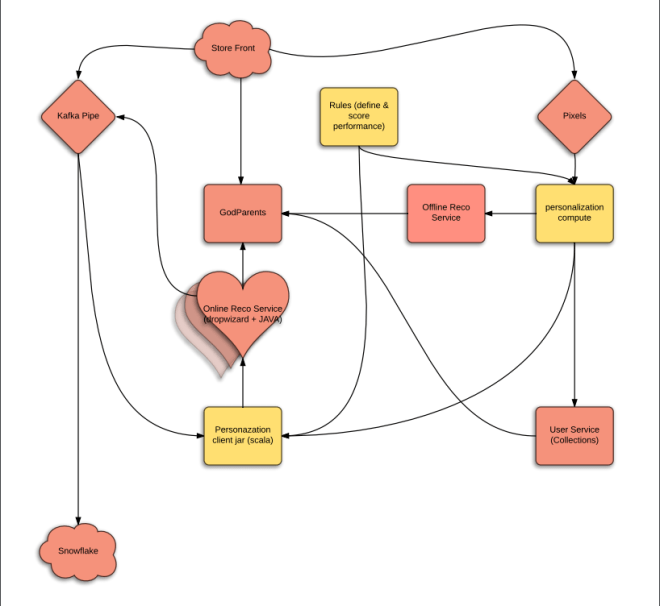
The yellow parts are new as well as the heart.
Being a software architect in early 00s makes me believe that I can still do it. However, I’m frequently wrong. Luckily John (Director of Engineering) and Jade (Director of Platoform services) took it over and rescued the drowning baby. They thought of all the edge cases and we made a lot of decisions on what we can and cannot do for MVP. Jay (Director of ETL) took over the pipeline cartoon drawing here and came up with a robust proposal that actually works with our new data warehouse – Snowflake.
The pink parts are owned by Engineering and yellow by Data Science.
OK, we have very rough edges for engineering. John is spearheading this. He broke it down with Engineering Leads (Rod and Devin) and the deeply talented engineering team (Christine, August, Denitza, Jon and Kaixi). He has all the way from user stories down to actual API requirements that MLLib needs to respond to. We also have an open question on language for the MLLib, so we are trying to get consensus.
But this seems possible to do in three sprints given the talent we have. Each sprint is 2 weeks, which is 10 working days each. So yeah, 30 days*.
This is parallel to the algorithms and design tracks. We will talk about that tomorrow.
Off to the races…
P.S got delayed posting this (today is Thursday, not Monday), but will try to keep the timeline.
PPS. Does the above sound interesting? Come work with us
<featured image via here>

[…] Live logging building a production recommendation engine in 30 days […]