Level: Beginner, circa 2014
Or I can haz fashion.
Here are some pretty pictures to motivate you

These are all ‘dreamt’ by a neural net. OK, now for the old bait and switch. Let’s talk Deep Learning for a second.
For the uninitiated, traditional machine learning works something like this. Say you are trying to predict housing prices using square footage. You have relevant data with those fields. So you plot the two and see if there appears to be a relationship.

Looks like there is. Usually, you start with a simple algorithm to learn that relationship. Let’s say we used linear for starters, which gets us –

price ~ 6.6 * lotsize + 34,136
Then you look at the errors, and you aren’t satisfied. Maybe this isn’t a straight line after all. Often the next thing to try is to transform the input parameters to make them look linear. So a typical transform in the above case would be natural log. Now the relationship looks like this
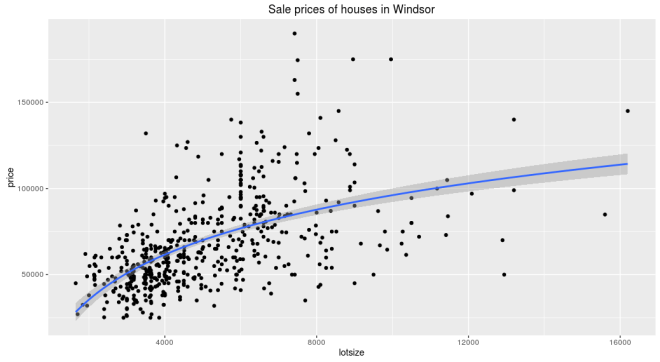
and equation
price ~ 37,660 * log(lotsize) - 250,728
And you are rewarded with better results. These sort of transforms are the bread and butter of traditional machine learning. But of course we prefer a fancier term, feature engineering.
But what are you really doing? You are transforming the input space to make the simple line fit. You still want to fit a line, but are mangling the input plane to make it go through that line. It’s like holding your breath to shimmy into a pair of jeans you have owned for longer than you should.
What if you could let the model transform the input all it needs, and build on top of the last transform one step at a time, to put the data in the right shape for your classifier? That’s exactly what deep learning does for you. And at the end, the last layer is a simple linear classifier.
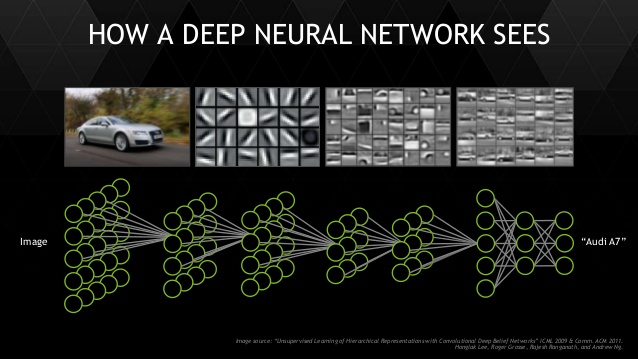
This isn’t exactly a new concept, Bayesians already do this. But they don’t have a fast enough algorithm yet and the models are a bit too custom – making it hard to generalize to a new problem.
We are going to talk about dresses, so the right data format happens to be photos. To a computer, that is a matrix of numbers of height x width x 3 channels (Red, Green, Blue).
Sidenote: The above representation is not perfect. It is important to note that photo format has limitations. In real life, you don’t have borders (padding), you can move your eyes and see further. Borders are a limitation of the medium. Real vision is a fluid and complex thing (mind fills in details, nose is invisible, etc). Photos are just a good approximation of that.
Convolution transforms are designed specifically to learn from this format. It’s job is to transform the input space spatially. So lower layers do versions of edge detection, blurring, etc. And higher layers begin to understand that the combination of which edges means a collar or a sleeve. Finally, linear classifier on top as before to figure out which dress it is. As before, the model learns which convolutions to do in order to achieve the final result. It is not taught edge detection specifically but it will decide to detect a particular edge if it makes it easy for the linear classifier.
Deep learning is responsible for some impressive results. However, those impressive results require lots of data. If you aren’t so lucky, there still are a few options.
One option is transfer learning. The basic idea is that you train the network to learn to distinguish between objects on a large dataset. Then freeze the early layers and train just the last few layers very slowly on your data for it to understand how the same corners it learnt by distinguishing cats and dogs. can be used to piece together a dress.
In my experience, this tends to overfit. In other words, it doesn’t work as well for new (unseen) data. And we don’t get those advertised 90+% accuracy.
So what else can we do?
Here is a crazy idea (thanks Ian Goodfellow, 2014). Why don’t we generate our own data?
There are other data augmentation techniques (adding noise to existing input, Bayesian techniques and others) but I was looking for an excuse to generate sharp pictures of dresses anyway. So that’s what we will do.
Our net that distinguishes between classes is called a discriminator (missed opportunity to call it connoisseur). For now, we will assume all it does is say whether or not what it sees is a dress.
The idea is to invert this discriminator to generate from noise. This is called a generator. This involves inverting the convolution to a deconv layer. The loss is also negative of the Discriminator loss.
We pitch the two nets against each other but with an odd setup. In the first half of the game, we sample real data and the discriminator tries to say that this is a dress. In the second half, the generator takes in random noise and comes up with a new dress. We then sample and feed that to our discriminator that tries to say that this is not a real dress. We then back propagate the errors through the whole thing.
Over time the discriminator tries to create fakes to fool the generator. And generator tries to guard against this treachery. This goes on till they reach an equilibrium. At this point the discriminator can no longer tell real from fake dresses (50/50). Yes guys, this was the time for game theory.

We now have two nets – a much better discriminator than before because it trained on a lot more data. And a generator that can generate decent fakery.
But you ask, I thought this was ‘sane’ alytics. Where is the practical stuff!
Well, the discriminator has been fed a steady diet of fake dresses and is better at telling real from fake than when it started. It overfits less because it has trained on more data. And sure, we get the generator for free. The images in this article are from the baseline (Alexnetish) generator but theoretically using something better like Resnet should work even better.
Here are some original sample pictures that we had for input

Here are some results from the generator after training.
And let’s make the distinction from adding noise to data. This is generating data from noise. See this transition to understand how it evolves over training iterations.
The discriminator learns to distinguish between this being a dress vs any fake samples. The generator plays the game and is still generating not very dress like samples at 500 iterations

And after 130,000 iterations, it can generate something like this

Here is a snippet of how it learns

While not perfect, this is impressive from two years ago when this was first introduced.
But wait, there is more. Folks have been able to generate new bedrooms, improve resolution of a photo (CSI Enhance!), make folks with RBF smile, predict what happens in the next frame of the video (compress) and generated colorful birds from text.
We don’t yet know everything GANs can do. But it is already proving to be a useful tool.
Want to generate on your own data? See DCGAN code from Facebook here and (more efficient!) WassersteinGAN here.
Want to learn more? Here is a deeper dive on different kinds of GANs.
This is a rapidly evolving field, so new papers come out all the time. We aren’t too far from dreaming up different dresses for everyone’s personal style and fit, at scale.
